スキャンしたデータにテキストデータを埋め込む
スキャナーで読み込んだ原稿を本機でOCR処理し、テキストデータをPDFに埋め込みます。

WSD宛先を使用しているときは、[ファイル形式/ファイル名]は表示されません。
この機能を使用するために必要なオプションについては、使用している機種の使用説明書を参照してください。
OCR処理できる文字数は、1ページあたり約4万文字です。
OCRで認識できる言語は、以下のとおりです。
英語、ドイツ語、フランス語、イタリア語、スペイン語、オランダ語、ポルトガル語、ポーランド語、スウェーデン語、フィンランド語、ハンガリー語、ノルウェー語、デンマーク語、日本語
[読み取り条件]の[原稿種類]タブで[白黒:写真]を設定して原稿を読み取ると、文字に階調処理がかかるため文字や天地が正しく識別されないことがあります。OCR処理を優先するときは、[読み取り条件]の[原稿種類]タブで[白黒:文字]を設定して読み取ることをお勧めします。
以下のときは設定できません。
ファイル形式で[TIFF/JPEG]または[TIFF]が選択されているとき
解像度に[100dpi]が選択されているとき
WSDまたはDSMの宛先を使用しているとき
[ファイル形式/ファイル名]を押します。
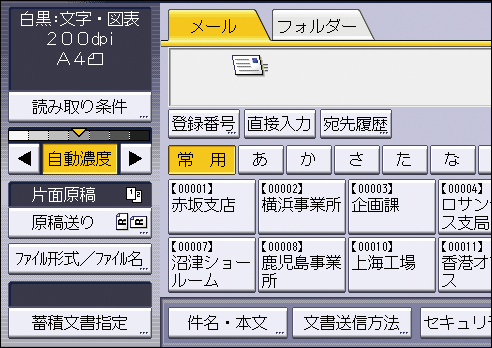
ファイル形式で[PDF]を押します。
PDFファイル設定の[OCR設定]を選択し、[する]を押します。
必要に応じて[自動ファイル名追加]、[白紙除去]または[認識言語]を設定します。
以下のときは[自動ファイル名追加]は選択できません。
[文書蓄積]で[本体に蓄積]を選択しているとき
以下のように設定しているとき
設定画面のタイプ:標準
[スキャナー設定] [送信設定] [メール設定(URLリンク)] [文書送信方法] [URLリンク添付]
[送信設定] [メール設定(URLリンク)] [文書送信方法] [URLリンク添付]設定画面のタイプ:従来
[スキャナー設定] [送信設定]タブ [文書送信方法] [URLリンク]
[OK]を2回押します。

200dpi以上の解像度で読み取りをしても、変倍設定で縮小すると実質的な解像度が200dpi未満となることがあります。このようなときでもOCR処理は実行されますが、OCRの認識精度が低下します。
文字の形や種類によっては正しく認識できないことがあります。
文字として認識される個所がないページは、通常のPDFとして生成されます。
原稿のプレビュー画像の天地と、読み取った結果(PDFファイル)の天地は必ずしも一致しません。
白紙の部分が多いページは天地が正しく認識できないことがあります。
全ページが白紙として検知されると、PDFファイルは生成されません。PDFファイルが生成されないときは、原稿のセット方法を確認してください。
原稿の裏写りや汚れによって、白紙が白紙として検知されないことがあります。また、天地が正しく認識できないことがあります。
OCR処理をしているときに原稿のフォントを判別しないため、原稿の文字幅と埋め込むテキストの文字幅の差異によって、埋め込まれたテキストの位置がずれることがあります。
全角と半角を誤って認識することがあります。PDFに埋め込まれたテキストを閲覧ソフトで検索するときは、全角と半角を区別しない設定にしてください。
OCRを設定し、連続して読み取るときは、2番目以降に読み取る原稿の用紙サイズや解像度によって、読み取り開始に時間がかかります。
PDFファイルに文書パスワードを設定し、暗号化して保護します。パスワードを設定したPDFファイルを開くには、パスワードの入力が必要です。
文書パスワードは、権限変更パスワードと同じものは使用できません。
WSD宛先を使用しているときは、[ファイル形式/ファイル名]は表示されません。
セキュリティーが設定できるファイル形式は、[PDF]または[クリアライトPDF]です。
暗号化の設定は、メール送信時、フォルダー送信時、外部メディアへの保存時だけできます。
文書パスワードを忘れると、暗号化したファイルを開くことができません。設定した文書パスワードは、忘れないように大切に保管しておいてください。
[ファイル形式/ファイル名]を押します。
ファイル形式で[PDF]を選択します。
必要に応じて[クリアライトPDF]を選択します。[セキュリティ設定]を押します。
[暗号化]タブが選択されていることを確認します。
文書暗号化の[する]を押します。
パスワードの[入力]を押します。
パスワードを入力して[OK]を押します。
文書パスワードは半角英数32文字まで入力できます。
ここで入力した文書パスワードは、PDFファイルを開くときに必要です。確認のためもう一度パスワードを入力し、[OK]を押します。
暗号化レベルから[40bit RC4]、[128bit RC4]、[128bit AES]、または[256bit AES]を選択します。
[OK]を2回押します。
暗号化レベルで[128bit RC4]を選択して作成したPDFファイルは、Adobe Acrobat Reader 3.0/4.0とは互換性がありません。
暗号化レベルで[128bit AES]を選択して作成したPDFファイルは、Adobe Reader 7.0以降のバージョンだけ互換性があります。
暗号化レベルで[256bit AES]を選択して作成したPDF ファイルは、Adobe Reader 9.0以降のバージョンだけ互換性があります。
暗号化レベルで[40bit RC4]を選択していると、セキュリティー権限項目の文書を印刷する権限で[低解像度のみ許可]は選択できません。
PDFファイルに権限変更パスワードを設定して、PDFファイルの印刷、変更、内容のコピーまたは抽出を制限します。権限変更パスワードを知っている人だけが、制限を解除または変更できます。
権限変更パスワードは、文書パスワードと同じものは使用できません。
WSD宛先を使用しているときは、[ファイル形式/ファイル名]は表示されません。
セキュリティーが設定できるファイル形式は、[PDF]または[クリアライトPDF]です。
権限変更パスワードを忘れると、ファイルの制限の解除または変更ができません。設定した権限変更パスワードは、忘れないように大切に保管しておいてください。
[ファイル形式/ファイル名]を押します。
ファイル形式で[PDF]を押します。
必要に応じて[クリアライトPDF]を選択します。PDFファイル設定の[セキュリティ設定]を押します。
[権限]タブを押します。
権限変更パスワードの[設定する]を押します。
パスワードの[入力]を押します。
パスワードを入力して[OK]を押します。
権限変更パスワードは半角英数32文字まで入力できます。
ここで入力したパスワードは、セキュリティーを設定したPDFファイルのセキュリティー権限を変更するときに必要です。確認のためもう一度パスワードを入力し、[OK]を押します。
セキュリティー権限項目を選択します。
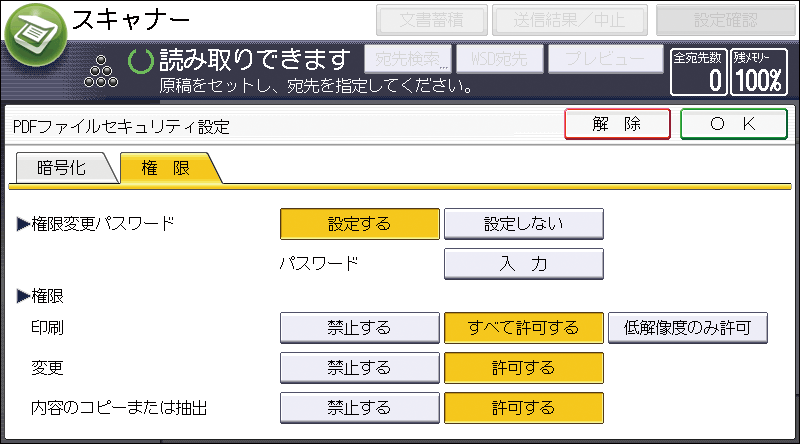
設定できるセキュリティー権限項目は以下のとおりです。
印刷(文書を印刷する権限)
[禁止する]、[すべて許可する]、[低解像度のみ許可]から選択します。変更(文書を変更する権限)
[禁止する]または[許可する]から選択します。内容のコピーまたは抽出(文書中のテキストをコピーまたは抽出する権限)
[禁止する]または[許可する]から選択します。
[OK]を2回押します。
PDFファイルの暗号化レベルで[40bit RC4]を選択していると、セキュリティー権限項目の文書を印刷する権限で[低解像度のみ許可]は選択できません。