
テキストデータを埋め込んだPDFとしてスキャンする
PDF閲覧用のアプリケーションでテキストの検索やコピーができるように、スキャンして作成したPDFにテキストデータを埋め込みます(OCR機能)。
クリアライトPDFやPDF/Aでもこの機能を使用できます。

この機能を使用するにはオプションのOCR変換モジュールが必要です。
以下のときは設定できません。
ファイル形式で[TIFF/JPEG]または[TIFF]が選択されているとき
解像度に[100 dpi]が選択されているとき
WSDまたはDSMの宛先を使用しているとき
RICOH Always Current Technology v1.1以前の機器
 ホーム画面で[スキャナー]を押す。
ホーム画面で[スキャナー]を押す。
 原稿をセットする。
原稿をセットする。
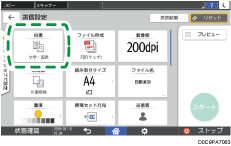
 スキャナー画面で[送信設定]を押す。
スキャナー画面で[送信設定]を押す。
 [ファイル形式]
[ファイル形式]![]() [その他]と押す。
[その他]と押す。

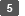 1ページだけのPDFを作成するときは[PDF(シングルページ)]、複数ページのPDFを作成するときは[PDF(マルチページ)]を押す。
1ページだけのPDFを作成するときは[PDF(シングルページ)]、複数ページのPDFを作成するときは[PDF(マルチページ)]を押す。
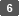 「PDF詳細設定」で[OCR]にチェックを付け、OCR処理のしかたを設定する。
「PDF詳細設定」で[OCR]にチェックを付け、OCR処理のしかたを設定する。
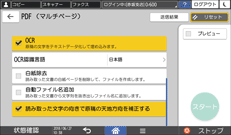
OCR認識言語:読み取る原稿と同じ言語を選択します。
白紙除去:白紙のページを除いてPDFを生成します。
自動ファイル名追加:ファイル名としてふさわしいと判断された文字列が自動的に抽出され、ファイル名の末尾に追加されます。文字列は先頭ページから抽出するため、先頭ページに文字が含まれていないときは、ファイル名に文字列は追加されません。
読み取った文字の向きで原稿の天地方向を補正する:OCRに成功した文字の向きをもとに、原稿の天地(上下)を識別します。
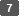 原稿種類で画質を選択する。
原稿種類で画質を選択する。
認識の精度を高くするときは、[白黒:文字]を選択します。
 スキャンした文書をメールアドレスに送信するときは、[送信者]を押し、送信者を指定する。
スキャンした文書をメールアドレスに送信するときは、[送信者]を押し、送信者を指定する。
 宛先を指定し、[スタート]を押す。
宛先を指定し、[スタート]を押す。

白紙に近いページは正しく天地(上下)を識別できないことがあります。
テキストデータを埋め込んだPDFを検索するときは、全角と半角を区別しない設定にすると文字が見つかりやすくなります。
原稿サイズや解像度によっては、次のページの読み取り開始に時間がかかります。
OCR処理できる文字数は、1ページあたり約4万文字です。
OCRで認識できる言語は、以下のとおりです。
英語、ドイツ語、フランス語、イタリア語、スペイン語、オランダ語、ポルトガル語、ポーランド語、スウェーデン語、フィンランド語、ハンガリー語、ノルウェー語、デンマーク語、日本語
200dpi以上の解像度で読み取りをしても、変倍設定で縮小すると実質的な解像度が200dpi未満となることがあります。このようなときでもOCR処理は実行されますが、OCRの認識精度が低下します。
文字の形や種類によっては正しく認識できないことがあります。
文字として認識される個所がないページは、通常のPDFとして生成されます。
全ページが白紙として検知されると、PDFファイルは生成されません。PDFファイルが生成されないときは、原稿のセット方法を確認してください。
原稿の裏写りや汚れによって、白紙が白紙として検知されないことがあります。また、天地が正しく認識できないことがあります。
OCR処理をしているときに原稿のフォントを判別しないため、原稿の文字幅と埋め込むテキストの文字幅の差異によって、埋め込まれたテキストの位置がずれることがあります。
RICOH Always Current Technology v1.2以降の機器
ホーム画面で[スキャナー]を押す。
原稿をセットする。
スキャナー画面で[送信設定]を押す。
[ファイル形式]![]() [その他]と押す。
[その他]と押す。

[PDF]、[クリアライトPDF]、または[PDF/A]を押す。
[OCR設定]を押し、OCR処理のしかたを設定する。
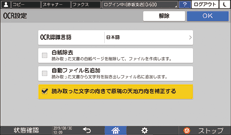
OCR認識言語:読み取る原稿と同じ言語を選択します。
白紙除去:白紙のページを除いてPDFを生成します。
自動ファイル名追加:ファイル名としてふさわしいと判断された文字列が自動的に抽出され、ファイル名の末尾に追加されます。文字列は先頭ページから抽出するため、先頭ページに文字が含まれていないときは、ファイル名に文字列は追加されません。
読み取った文字の向きで原稿の天地方向を補正する:OCRに成功した文字の向きをもとに、原稿の天地(上下)を識別します。
[OK]をクリックする
[原稿種類]で画質を選択する。
認識の精度を高くするときは、[白黒:文字]を選択します。
スキャンした文書をメールアドレスに送信するときは、[送信者]を押し、送信者を指定する。
 宛先を指定し、[スタート]を押す。
宛先を指定し、[スタート]を押す。
白紙に近いページは正しく天地(上下)を識別できないことがあります。
テキストデータを埋め込んだPDFを検索するときは、全角と半角を区別しない設定にすると文字が見つかりやすくなります。
原稿サイズや解像度によっては、次のページの読み取り開始に時間がかかります。